
目录
在开发的过程中,使用事务与锁是解决一些问题最常用的方式,但是当这俩个结合起来你真的会用吗?在高并发的场景下会出现哪些问题?要如何避免这些问题?接下来,带你了解事务与锁之间真正的打开方式。
开发过程中,扣减库存是最经典的场景之一,接下来以此场景模拟扣减库存的代码实现
场景模拟
java // 实体 @Data public class MaterialStock { /** * 物料库存id */ private Long id; /** * 物料名称 */ private String name; /** * 库存数量 */ private Long stockNum; }
java // 加锁 - 此处等同于分布式锁 ReentrantLock lock = new ReentrantLock(); // 实现方法 @SneakyThrows @Override @Transactional public void updateById(Long id) { lock.lock(); try { // 查询物料库存,扣减,然后更新库存 MaterialStock materialStock = materialStockMapper.selectById(id); Long stockNum = materialStock.getStockNum(); if (materialStock.getStockNum() <= 0) { log.info("库存不足"); return; } materialStock.setStockNum(stockNum - 1); materialStockMapper.updateById(materialStock.getId(), materialStock.getStockNum()); log.info("当前库存数量:{}\t,更新后库存数量:{}", stockNum, materialStock.getStockNum()); // 其他处理,耗时 500ms TimeUnit.MILLISECONDS.sleep(500); }finally { // 释放锁 lock.unlock(); } }
java // 单元测试 public void test3(){ for (int i = 0; i < 30; i++) { new Thread(() -> customExecutorService.updateById(1L)).start(); } }
接下来,模仿并发下的场景,设置20个库存,使用30个线程同步进行扣减,查看库存扣减的情况
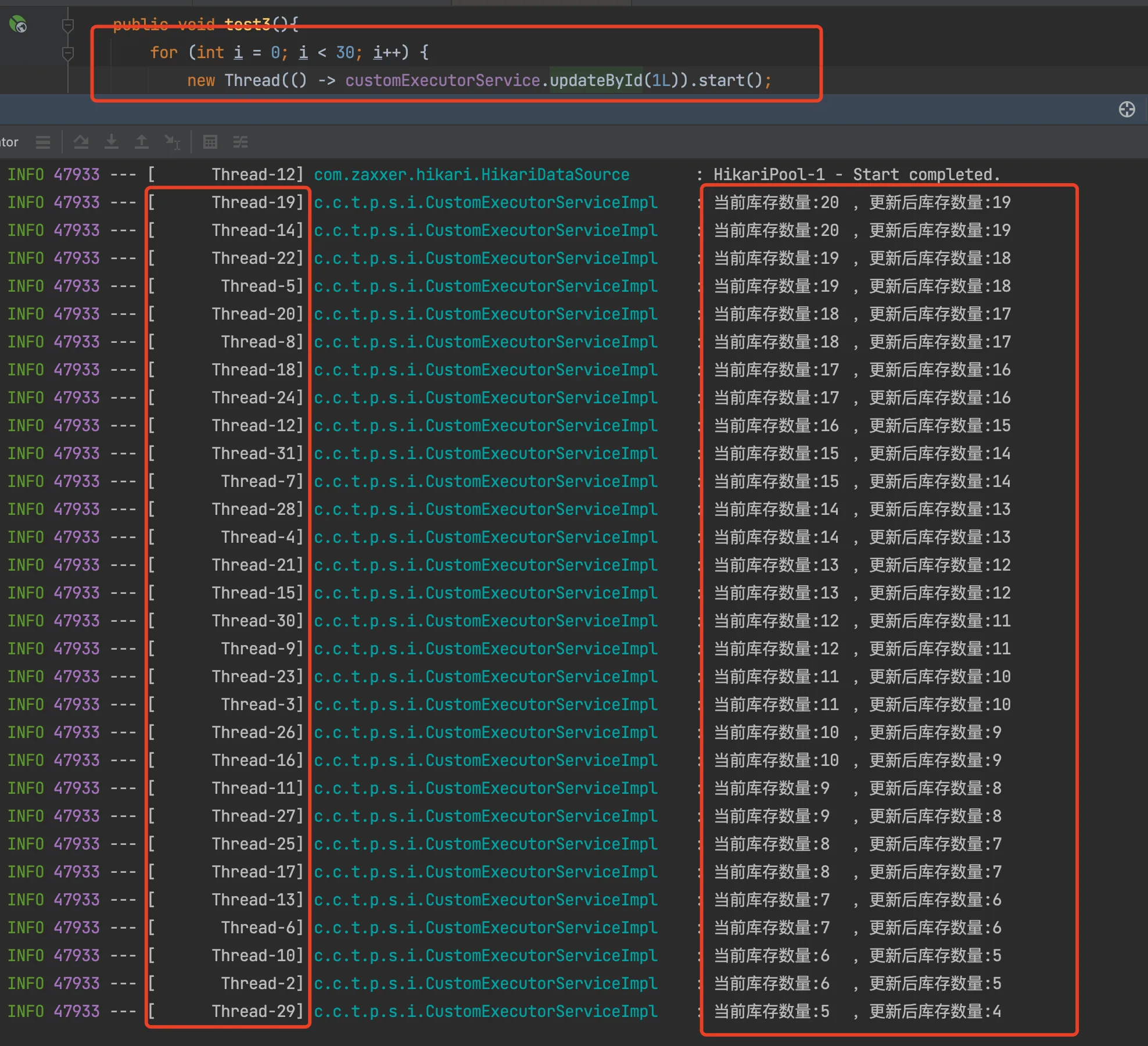
可以发现,库存中出现了少扣的情况,按照我们预想的执行,流程上应该是【加锁 -> 查询库存 -> 扣减库存 -> 更新库存 -> 释放锁】,数据上【线程数 30 - 库存数 20 = 剩余库存数 10】
现在看来,锁应该是失效了,那这是怎么回事呢?
代码分析
首先分析,一定是在【查询库存】的环节异常,将上次扣减的库存查询出来,那出现这种情况只有两种可能性,一种是【加锁】环节没有生效,一种就是【更新库存】没有执行成功,目前代码上加锁逻辑没有任何问题,那么出现问题的就只能是【更新库存】了,通过对更新库存的操作进行断点,我们查看库存的扣减情况,下面过程中发现当【更新库存 -> 释放锁】的步骤执行完,数据库中的数据并没有更新,事务并没有提交。
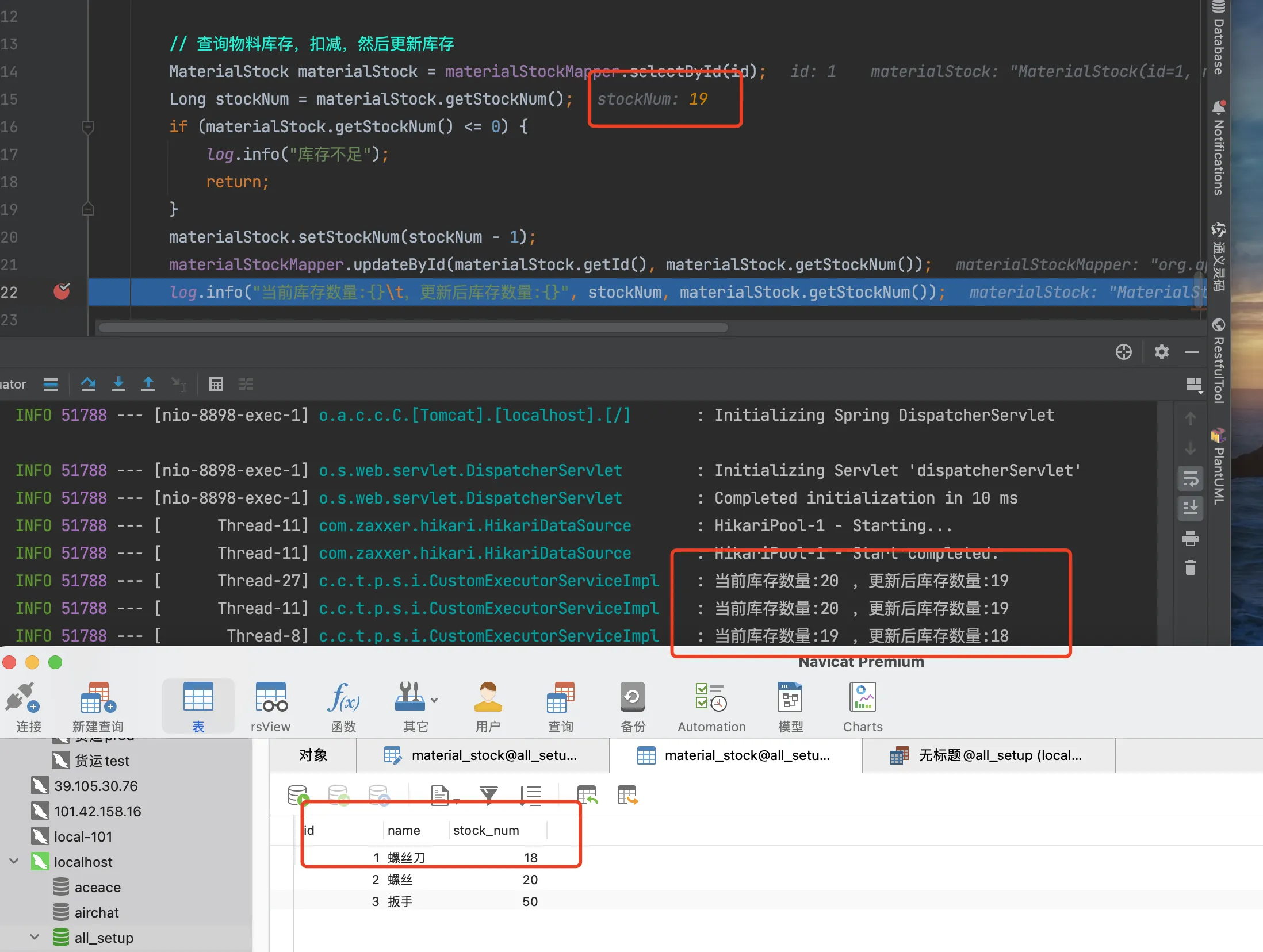
上面场景中,上一次线程库存数量已更新为18个,但是当前线程读取到的还是19个,且对此库存进行扣减,初步分析为上一个事务没有提交,当前线程就已经读取库存了。
说到这,了解事务实现原理的童鞋可能已经分析出来了,事务底层是通过aop实现,aop底层又是动态代理对象实现,此时上一个线程update方法执行结束,锁已经释放了,但是整个service方法还没有执行结束,后置处理中的事务还没有提交,其他线程此时开始加锁读取库存数量,就导致了此问题的产生。
解决方式
解决方式就比较多了,根据不同业务复杂度,可做不同的处理
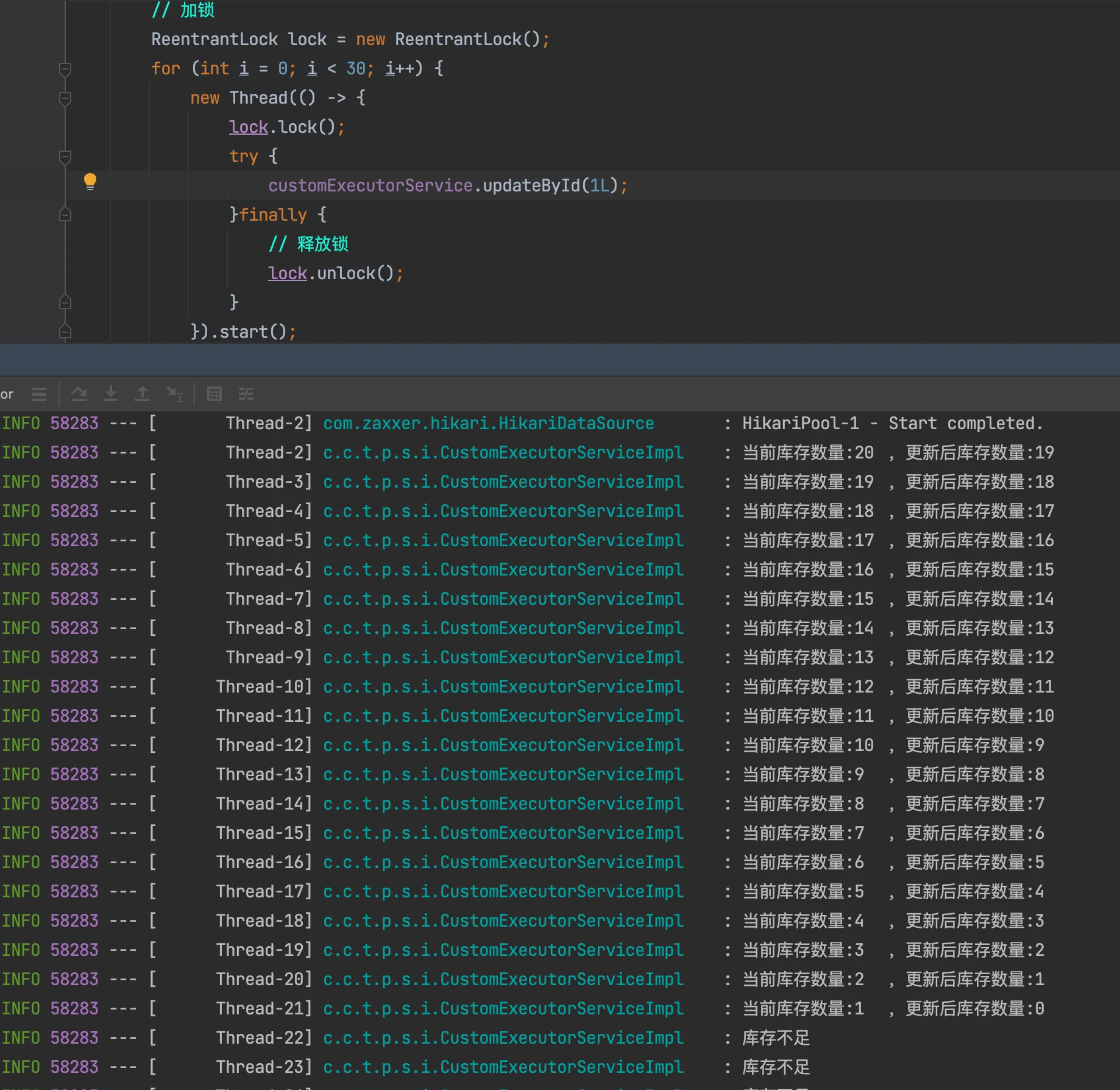
1、业务场景简单的情况,将锁直接提到上层,调用带事务的service即可
java public void test3(){ // 加锁 ReentrantLock lock = new ReentrantLock(); for (int i = 0; i < 30; i++) { new Thread(() -> { lock.lock(); try { customExecutorService.updateById(1L); }finally { // 释放锁 lock.unlock(); } }).start(); } }
查看数据,发现正常扣减了
2、业务场景复杂的情况,要考虑锁的力度,根据业务逻辑拆分接口,可将逻辑校验都提到代码最前方,将库存校验留到校验的最后,且与更新库存进行绑定,进行加锁处理,流程如下
java // 加锁 - 此处等同于分布式锁 ReentrantLock lock = new ReentrantLock(); @Override public void updateById(Long id) { try { // 其他逻辑处理... lock.lock(); // 处理事务 stockNum(id); }finally { // 释放锁 lock.unlock(); } } @SneakyThrows @Transactional void stockNum(Long id) { // 查询物料库存,扣减,然后更新库存 MaterialStock materialStock = materialStockMapper.selectById(id); Long stockNum = materialStock.getStockNum(); if (materialStock.getStockNum() <= 0) { log.info("库存不足"); return; } materialStock.setStockNum(stockNum - 1); materialStockMapper.updateById(materialStock.getId(), materialStock.getStockNum()); log.info("当前库存数量:{}\t,更新后库存数量:{}", stockNum, materialStock.getStockNum()); // 其他IO处理,耗时 500ms TimeUnit.MILLISECONDS.sleep(500); }
总结
解决这个问题的本质,就是不要将锁,放到被事务方法中,同时也要思考如果是其他aop切面或者自定义代理了方法会不会有影响。
往往开发的过程中使用的技术体系与底层的实现原理息息相关,掌握原理带动大脑思考
本文作者:ZhangHao
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!