
目录
回想当年 “你发任你发,我用Java 8”,对于老程序员来说,Java8 是陪伴我们学习与工作最长时间的版本了。当下 AI 浪潮的兴起,Java8 已成过去式,作为曾经的编程语言王者,Java 的更新速度令无数开发者望尘莫及,转瞬间,其版本已经来到了 25 是最新的长期支持(LTS)版本,相比常规的半年期版本,LTS 版本将获得更长周期的维护与支持 —— JDK 25 将获得至少 8 年的 Oracle Premier 商业支持,今天我们来探索一下 JDK 的新特性与变迁。
有兴趣可以去官方报告查看 《Java 25正式到来》

微服务体系的版本说明
在进行开发时,各组件之间的版本兼容性非常重要。以下是截至 2025 年 的主流版本兼容关系总结,帮助你避免“版本地狱”。
我们从微服务版本与 JDK 版本关系进行入手: Spring Cloud Alibaba 版本发布说明
新出的官方文档不太稳定,上述连接失效的话,可以到 Github 上查看 Spring Cloud Alibaba 版本发布说明
Spring Boot 官方推荐的 JDK & Maven 版本
Spring Boot 官方文档 明确说明了每个大版本支持的生命周期,其对应的 Java(JDK)版本范围 和 Maven 最低版本要求。
| Spring Boot 版本 | 支持的 JDK 范围 | 推荐 JDK | 最低 Maven 版本 | 是否支持 Jakarta EE 9+ |
|---|---|---|---|---|
| 3.3.x (2024.11+) | JDK 17 ~ 23 | JDK 21 | 3.6.3+ | ✅ 是(jakarta.* 包) |
| 3.2.x | JDK 17 ~ 21 | JDK 21 | 3.6.3+ | ✅ 是 |
| 3.1.x | JDK 17 ~ 20 | JDK 17 | 3.6.3+ | ✅ 是 |
| 3.0.x | JDK 17+ only | JDK 17 | 3.6.3+ | ✅ 是(重大变更) |
| 2.7.x (LTS) | JDK 8 ~ 19 | JDK 17 | 3.5.0+ | ❌ 否(仍用 javax.*) |
| 2.6.x 及更早 | JDK 8 ~ 17 | JDK 8/11 | 3.5.0+ | ❌ 否 |
🔔 重要提示
Spring Boot 3.x 起,不再支持 JDK 8/11,最低要求 JDK 17
Spring Boot 3.x 全面迁移到 Jakarta EE 9+,包名从 javax.servlet → jakarta.servlet
Spring Boot 4.0 的更新
Spring Boot 4.0 正式版已于 2025 年 11 月 21 日发布,标志着 Spring 生态的重大升级,核心聚焦 Java 21 原生支持、性能提升与云原生强化。
- Spring Boot 4.0 基于 Java 21+ 虚拟线程(Virtual Threads)特性,重构线程池模型,通过简单配置(如
spring.threads.virtual.enabled=true)即可实现 “百万级并发” 支持。 - 内置容器(Tomcat 11+/Jetty 12.1)全面适配虚拟线程,Web 服务并发能力提升 50% 以上。
- 将 GraalVM 原生编译从 “实验特性” 升级为 “生产级支持”,支持将应用编译为原生镜像(Native Image),冷启动时间可从 500ms 缩短至 50ms 以内,通过 AOT(提前编译)技术实现启动速度与内存占用的 “数量级优化”
- 日常的开发体验大升级,引入声明式 HTTP 客户端,类似
@HttpExchange的原生注解,不再需要OpenFeign等第三方库,就能用接口定义的方式优雅地调用 HTTP 接口,代码量减少约 60%。同时增加了 API 版本控制,在@RequestMapping等注解新增了version属性,无需在 URL 路径中硬编码/v1、/v2,即可轻松管理 API 的多版本共存。
Spring Boot 4.0 被视为未来 3-5 年 Java 后端开发的主流选择,核心优势在于 “快(虚拟线程)、简(配置)、适配云(原生生态)”。
JDK 11:现代化的基石 (LTS)
JDK 11 是继 JDK 8 之后非常重要的一个转折点,移除了很多过时的内容,并引入了现代语言特性。
局部变量类型推断 var
局部变量类型推断 (Java 10),这是 Java 10 引入的特性,允许编译器根据右侧的赋值自动推断左侧变量的类型。
java // 传统写法:需要重复书写类型,代码显得冗长 String name = "小柳"; List<String> namesList = Arrays.asList("Alice", "Bob", "Charlie"); Map<String, Integer> idMap = new HashMap<String, Integer>(); // 编译器自动推断类型,代码更简洁 var name = "小柳"; // 推断为 String var namesList = Arrays.asList("Alice", "Bob", "Charlie"); // 推断为 List<String> var idMap = new HashMap<String, Integer>(); // 推断为 HashMap<String, Integer>
Lambda 参数使用 var (Java 11),这是 Java 11 对 Lambda 表达式的增强。在 Java 11 之前,Lambda 参数要么写死类型,要么完全省略类型(由编译器推断),但不能在省略类型的同时添加注解。
java // 传统写法:必须写出 String 类型才能加 @NonNull 注解 List<String> list = items.stream() .map((@NonNull String s) -> s.toLowerCase()) .collect(Collectors.toList());
Java 11 允许你在 Lambda 参数中使用 var,这样既保留了类型推断的便利,又允许你添加注解。
java import java.util.*; import java.util.function.Function; import javax.validation.constraints.NotNull; public class LambdaVarExample { public static void main(String[] args) { List<String> items = Arrays.asList("Apple", "Banana", "Cherry"); // 1. 基本用法:使用 var 进行类型推断 // 编译器会推断 'var s' 为 String 类型 Function<String, Integer> strLength = (var s) -> s.length(); System.out.println(strLength.apply("Hello")); // 输出: 5 // 2. 结合注解使用(这是核心价值) // 现在可以给推断出的参数添加 @NotNull 等注解 List<String> result = items.stream() .map((@NotNull var s) -> { // IDE 或静态分析工具(如 Checker Framework)可以利用这个注解 // 确保 s 在这里不会是 null return s.toUpperCase(); }) .collect(Collectors.toList()); System.out.println(result); // 输出: [APPLE, BANANA, CHERRY] } }
注意
var 是局部变量类型推断,它只在方法内部有效,且必须在声明时初始化。它不是关键字,而是一个保留类型名,编译后字节码中依然是具体的类型(如 String 或 Object)。
String 字符串
在 Java 11 之前,处理空字符串、换行符分割或重复字符串通常需要借助 Apache Commons Lang 库(如 StringUtils)或自己写正则。Java 11 将这些常用功能直接内置了,增加了 isBlank(), lines(), strip(), repeat() 等实用方法,处理字符串更方便。
isBlank():判断字符串是否为空白(即只包含空白字符或长度为 0)。
java // Java 11 之前:通常需要使用 Apache Commons Lang 的 StringUtils.isBlank() // if (str == null || str.trim().length() == 0) { ... } // Java 11+ String str1 = ""; String str2 = " "; String str3 = " hello "; System.out.println(str1.isBlank()); // true System.out.println(str2.isBlank()); // true System.out.println(str3.isBlank()); // false (因为里面有字符)
lines():将字符串按换行符分割,返回一个Stream<String>。处理多行文本非常方便。
java String multiline = "Apple\nBanana\nCherry"; // Java 11 之前:通常用 split,但处理流不太方便,且会有数组转换的开销 // String[] arr = multiline.split("\n"); // Java 11+ multiline.lines() .filter(line -> line.contains("a")) // 只保留包含 'a' 的行 .map(String::toUpperCase) // 转为大写 .forEach(System.out::println); // 输出 // 输出: // APPLE // BANANA
strip()/stripLeading()/stripTrailing():相比旧的trim(),这些方法使用 Unicode 标准来识别空白字符,更安全、更准确(trim()只能处理小于\u0020的 ASCII 空白)。
java // 假设有一个带空格的字符串 String spaced = " Hello World "; // strip() 等同于以前的 trim(),但更符合现代标准 System.out.println("'" + spaced.strip() + "'"); // 'Hello World' System.out.println("'" + spaced.stripLeading() + "'"); // 'Hello World ' System.out.println("'" + spaced.stripTrailing() + "'");// ' Hello World'
repeat(int count):将字符串重复 N 次。
java // Java 11 之前:需要写循环或者使用 StringUtils.repeat() // for (int i = 0; i < 3; i++) sb.append(str); // Java 11+ String str = "Java"; String repeated = str.repeat(3); System.out.println(repeated); // 输出: JavaJavaJava // 常用于生成分隔线 System.out.println("-".repeat(20)); // 输出: --------------------
HTTP Client (标准版)
在 Java 11 中,HttpClient API 正式成为标准(之前在 Java 9/10 中是孵化状态),不再需要 Apache HttpClient 或 OkHttp(虽然大家还是习惯用第三方库,但标准库终于有了),支持 HTTP/2 和 WebSocket,支持同步和异步(非阻塞)调用,完全替代了老旧、难用的 HttpURLConnection。
java // 创建客户端 HttpClient client = HttpClient.newHttpClient(); // 构建请求 HttpRequest request = HttpRequest.newBuilder() .uri(URI.create("http://liushigong.cn")) .timeout(Duration.ofSeconds(10)) .GET() .build(); // 发送请求 (同步) HttpResponse<String> response = client.send(request, BodyHandlers.ofString()); System.out.println("Status code: " + response.statusCode()); System.out.println("Body: " + response.body());
单文件源代码运行 (Launch Single-File Source-Code Programs) 🚀
Java 11 允许你直接运行 .java 源文件,无需先执行 javac 编译,非常适合编写脚本、学习 Java 或编写简单的工具类,省去了编译打包的繁琐步骤。
sh java HelloWorld.java
JVM 特性
Java 11 新增了 ZGC(可扩展低延迟垃圾收集器),处于实验性阶段,为了实现的目标是解决大内存(TB 级)下的停顿时间问题,目标是将停顿时间控制在 10ms 以内。
注意
在 Java 11 中它是实验性的(需要通过 JVM 参数解锁),直到 Java 15 才正式转正。
Epsilon GC(无操作垃圾收集器),正式阶段(Java 11),分配内存但不回收内存(No-Op)。适用于性能测试、内存压力测试、生命周期极短的任务。它可以帮助你测量应用在“没有 GC 干扰”下的理论最高性能。
Flight Recorder (JFR)(飞行记录器),低开销的数据收集框架,用于对 Java 应用和 HotSpot JVM 进行故障排除。以前这是 Oracle JDK 商业版的特权,Java 11 将其开源并纳入 OpenJDK,可用于生产环境的性能剖析和诊断。 JDK Flight Recorder 官方文档
低开销堆分析,通过 JVM 工具接口(JVMTI)提供了一种低开销的堆分配采样方法,帮助开发者在生产环境中以极低的性能代价监控内存分配情况,定位内存泄漏问题。
JDK 17:代码简洁性的飞跃 (LTS)
JDK 17 进一步简化了代码编写,引入了很多“语法糖”,让 Java 代码看起来更像现代编程语言。
Records(一行定义 DTO)
以前我们需要写很多行代码来定义一个简单的数据载体类,现在只需要一行。
java // 传统写法(POJO) public class Person { private final String name; private final int age; public Person(String name, int age) { this.name = name; this.age = age; } // 需要手动生成或写大量的 getter, equals, hashCode, toString... public String getName() { return name; } public int getAge() { return age; } // ... 省略 50 行代码 ... } // JDK 17+ 写法(Record):编译器会自动为你生成:私有字段、公共构造函数、getter(同名)、equals、hashCode、toString public record Person(String name, int age) { } // 使用示例 public class Main { public static void main(String[] args) { Person person = new Person("Alice", 30); System.out.println(person.name()); // 直接调用 getter System.out.println(person); // 输出: Person[name=Alice, age=30] } }
Pattern Matching for instanceof(模式匹配)
告别繁琐的“先判断再强转”流程。
java // 传统写法 if (obj instanceof String) { String s = (String) obj; // 需要手动强转 System.out.println(s.toUpperCase()); } // JDK 17+ 写法:编译器自动识别类型,无需强转 // 's' 的作用域仅限于 if 块内 if (obj instanceof String s) { // 变量 's' 在此处已经自动转换为 String 类型 System.out.println(s.toUpperCase()); }
Switch 表达式(箭头语法与 yield)
让 switch 更加函数式,避免 break 遗漏导致的穿透问题。
java // 传统写法(语句) String day; switch (dayOfWeek) { case MONDAY: case TUESDAY: day = "Week Start"; break; // 容易忘记写 break case FRIDAY: day = "Weekend Soon"; break; default: day = "Midweek"; break; } // JDK 17+ 写法(表达式) // 1. 使用 -> 箭头(不需要 break) // 2. 可以使用 yield 返回值 String day = switch (dayOfWeek) { case MONDAY, TUESDAY -> "Week Start"; case FRIDAY -> "Weekend Soon"; default -> { System.out.println("Processing..."); yield "Midweek"; // 在代码块中使用 yield 返回值 } };
Sealed Classes(密封类)
限制谁可以继承我,增强封装性。
java // 1. 定义一个密封类,只允许 Circle 和 Rectangle 继承 public abstract sealed class Shape permits Circle, Rectangle { abstract double area(); } // 2. 具体的子类必须在同一个模块/包下,并且必须是 final、sealed 或 non-sealed 之一 final class Circle extends Shape { final double radius; Circle(double radius) { this.radius = radius; } double area() { return Math.PI * radius * radius; } } final class Rectangle extends Shape { final double length, width; Rectangle(double length, double width) { this.length = length; this.width = width; } double area() { return length * width; } } // 其他类无法继承 Shape,这在使用 switch 处理枚举-like 结构时非常安全
JVM 特性
ZGC & Shenandoah 生产就绪,可以正式应用,这不是代码层面的改变,而是 JVM 启动参数的改变,目标是解决大堆内存(TB 级)下的长时间停顿问题。
bash # 启用 ZGC (Java 17 中已非常成熟) java -XX:+UseZGC -Xmx4g MyApp # 启用 Shenandoah GC java -XX:+UseShenandoahGC -Xmx4g MyApp
强封装 JDK 内部 API (Strongly Encapsulate JDK Internals)
这主要影响那些使用反射去调用 JDK 内部私有 API(如 sun.misc.Unsafe 以外的内部类)的代码。如果你的旧项目使用了 sun.* 包下的非标准 API,升级到 JDK 17 后可能会报错 IllegalAccessException 或 NoSuchFieldException。
- 解决方案:修改代码,使用标准的公开 API 替代内部 API。
- 临时方案:如果必须使用,可以通过 JVM 参数打开特定包的访问权限(不推荐用于长期方案)
bash # 例如,允许所有代码读取 java.base 模块(不安全,仅用于兼容旧库) java --permit-illegal-access ... # 或者更细粒度地开放某个包 java --add-opens java.base/sun.nio.ch=ALL-UNNAMED ...
JDK 21:并发编程的革命 (LTS)
JDK 21 引入了虚拟线程,这是 Java 并发模型 20 年来最大的一次变革,旨在让 Java 轻松实现百万级并发。
并发核心(虚拟线程 Virtual Threads)
长期以来,我们的请求模型一直是 “一请求一线程”(Thread-per-Request)。这意味着,每当有一个新的 HTTP 请求进来,Web 服务器(如 Tomcat)就会分配一个独立的线程去处理。
在 JDK 21 之前,Java 的 Thread 直接映射到操作系统的内核线程(Platform Thread),一个 Java 线程对应一个操作系统线程(昂贵)
- 内存贵:一个平台线程默认占用约 1MB - 2MB 的栈内存。
- 切换慢:线程上下文切换涉及内核态与用户态的转换,开销巨大。
- 数量受限:你很难在一台普通服务器上启动几万个线程,机器会直接卡死。
为了解决高并发问题,我们被迫引入了 NIO、Netty、WebFlux 等异步框架。虽然吞吐量上去了,但代价是惨痛的:
- 代码难懂:逻辑被拆得支离破碎,回调地狱(Callback Hell)随处可见。
- 调试噩梦:一旦报错,堆栈追踪(Stack Trace)里全是框架代码,根本找不到业务逻辑的源头。
JDK 21 虚拟线程的出现,就是为了打破这个僵局,它允许你用最熟悉的“同步阻塞”代码风格,写出媲美异步框架的“高并发性能”。
什么是虚拟线程?
虚拟线程(Virtual Threads) 是一种由 JVM 自身管理的轻量级线程,它不再与操作系统的内核线程 1:1 绑定,现在虚拟线程由 JVM 调度,可以轻松创建百万个。
我们可以做一个简单的对比:
| 特性 | 平台线程 (Platform Thread) | 虚拟线程 (Virtual Thread) |
|---|---|---|
| 管理者 | 操作系统内核 | JVM 虚拟机 |
| 映射关系 | 1:1 (一个 Java 线程对应一个 OS 线程) | M:N (大量虚拟线程复用少量 OS 线程) |
| 创建成本 | 昂贵 (MB 级内存,系统调用) | 极低 (几百字节,普通 Java 对象) |
| 数量上限 | 几千个 | 几百万个 (仅受堆内存限制) |
简单来说,虚拟线程就像是 Java 中的“协程”(Go 语言的 Goroutine),但它完全融入了现有的 java.lang.Thread API,老代码几乎不用改就能享受红利。
工作核心原理
JDK21 虚拟线程采用 M:N 调度模型,大量虚拟线程(M) 可映射到少量平台线程(N),其中 M 通常远大于 N。这一模型的核心在于由 JVM 管理调度,虚拟线程作为轻量级用户态线程,共享平台线程资源,从而突破传统线程的性能瓶颈,相比于平台线程,虚拟线程初始栈空间仅4KB(传统线程约1MB),创建/销毁开销极低。
为了更好的理解虚拟线程,我用一个"出租车接人模型"来打比方。
出租车公司(操作系统 OS):只有 10 辆出租车(这是你的 CPU 核心数/载体线程 Carrier Threads)。 乘客(任务 Task):有 10,000 名乘客(这是你的并发请求)。
传统模式(平台线程)
每辆车一次只能拉一个乘客。如果乘客半路说:“师傅,我要去取个快递(数据库查询/网络请求),你等我 5 分钟。” 这时候,出租车就真的停在路边死等(线程阻塞)。因为车只有 10 辆,一旦都在等人,后面 9990 个乘客只能排队喝西北风。这就是为什么传统线程池并发上不去。
虚拟线程模式
在 JDK 21 中,情况变了:
- 挂载(Mount):乘客坐上出租车,开始计算任务。
- 卸载(Unmount):当乘客需要等红灯或取快递(遇到阻塞 I/O,如 Thread.sleep 或 DB 查询)时,JVM 会立刻让乘客下车,把他的状态(Continuation)存在路边。
- 复用:出租车(载体线程)立刻去拉下一个乘客,一刻也不闲着。
- 恢复:当原来的乘客快递取好了(I/O 完成),他会重新排队,等任意一辆空闲的出租车过来,带上之前的状态继续走。
结果:仅用 10 辆车,就让 10,000 个乘客感觉自己都在“同时”前进。CPU 利用率被榨干到了极致。
本质
虚拟线程的本质就是通过一个平台线程,管理了众多的虚拟线程,在IO密集型场景下,虚拟线程阻塞时不会占用平台线程,避免资源浪费。针对于我们的IO密集型任务(如数据库访问、网络调用),通过让渡 CPU 资源提升整体的并发规模。
实战应用
不需要引入任何第三方包,即可直接创建虚拟线程:
java // 方式 1: 直接启动一个虚拟线程 Thread.startVirtualThread(() -> { System.out.println("Hello from Virtual Thread: " + Thread.currentThread()); }); // 方式 2: 使用 Builder 构建更详细的配置(如名称) Thread vThread = Thread.ofVirtual() .name("my-vthread") .start(() -> { // 业务逻辑 });
可以直接替代线程池,这是最大的思维转变。过去我们用 Executors.newFixedThreadPool(200) 来限制线程数量。 现在,请忘掉线程池! 虚拟线程是用完即毁的,不需要池化。
java // 使用 try-with-resources 自动关闭结构 try (var executor = Executors.newVirtualThreadPerTaskExecutor()) { IntStream.range(0, 10_000).forEach(i -> { executor.submit(() -> { // 模拟耗时 I/O 操作,例如调用第三方 API Thread.sleep(Duration.ofSeconds(1)); return i; }); }); } // 代码运行到这里,说明 10,000 个任务全部执行完毕。 // 在传统线程池下,这可能需要几十秒;而在虚拟线程下,耗时仅约 1 秒多一点。
记录模式 (Record Patterns)
它允许你在 instanceof 或 switch 中直接解构 Record 对象,无需手动调用 getter。
java // 定义一个 Record record Point(int x, int y) {} // 传统写法:类型判断 + 强转 + 取值 if (obj instanceof Point) { Point p = (Point) obj; System.out.println(p.x() + ", " + p.y()); } // Java 21 写法:一行搞定 if (obj instanceof Point(int x, int y)) { System.out.println(x + ", " + y); // 直接解构出 x 和 y 变量 } // 在 switch 中使用 switch (obj) { case Point(int x, int y) -> System.out.println("坐标: " + x + ", " + y); case null -> System.out.println("null"); default -> System.out.println("未知类型"); }
序列化集合 (Sequenced Collections)
为集合家族(List, Set, Deque)提供了统一的操作首尾元素的 API。
java // 以前:List 没有 getFirst()/getLast(),需要转为 Deque 或用索引 List<String> list = new ArrayList<>(); list.add("A"); list.add("B"); // Java 21 写法 if (!list.isEmpty()) { String first = list.getFirst(); // 直接获取第一个 String last = list.getLast(); // 直接获取最后一个 System.out.println(first + ", " + last); } // 还有一个新方法 reversed(),返回逆序视图 for (String s : list.reversed()) { System.out.println(s); // 倒序输出 }
JVM 优化
ZGC 在 Java 15 时还是实验性的,到了 Java 17 可用,而在 Java 21 中引入了分代收集,这是巨大的性能提升。
以前(不分代)ZGC 采用全堆并发回收,虽然停顿时间极短(<10ms),但对于大量“朝生夕灭”的短生命周期对象,回收效率不如分代回收器(如 G1)。
而 Java 21(分代 ZGC)引入了年轻代和老年代的概念,JVM 会优先回收年轻代,减少全局扫描频率。对于典型的业务应用,吞吐量获得极大的提升,同时还将 CPU 占用降低,使得内存回收更高效,减少了不必要的 CPU 开销。
bash # 启用 ZGC -XX:+UseZGC # 开启分代模式 -XX:+ZGenerational
JDK 25:更轻量、更安全 (LTS - 2025年9月发布)
Java 25 作为最新的长期支持(LTS)版本,更多关注底层性能优化、内存节省以及面向未来的技术储备。其优化策略非常明确:让并发编程更安全、让代码书写更极简、让底层性能更极致。
以下是我整理的 Java 25 核心优化点及代码示例。
并发编程的“安全带”:作用域值 (Scoped Values)
在虚拟线程场景下,ThreadLocal 会有性能问题和内存泄漏风险,而 Scoped Values 提供了一种更高效、不可变的线程间数据共享方式,同时会自动清理数据,特别适合在虚拟线程(Virtual Threads)场景下传递上下文。解决了传统的 ThreadLocal 在虚拟线程池中会导致内存泄漏或数据错乱,且需要手动 remove()。
java // 1. 定义一个 ScopedValue (通常作为静态常量) static final ScopedValue<String> CURRENT_USER = ScopedValue.newInstance(); public class ScopedValueDemo { public static void main(String[] args) { // 2. 在指定的作用域内绑定值并执行任务 ScopedValue.where(CURRENT_USER, "Alice") .run(() -> { // 在这里可以安全地获取值 System.out.println("Hello, " + CURRENT_USER.get()); // 无需手动清理,作用域结束自动销毁 }); // 3. 支持嵌套和继承 ScopedValue.where(CURRENT_USER, "Bob") .call(() -> processOrder()); } static void processOrder() { // 这里会打印 "Bob",且不会受到其他线程/虚拟线程的干扰 System.out.println("Processing order for: " + CURRENT_USER.get()); } }
内存与性能的硬核优化:紧凑对象头 (Compact Object Headers)
这是一个 JVM 层面的“隐形”优化,无需改代码,只需开启参数,就能显著降低内存占用。传统的 Java 对象头(Object Header)包含 Mark Word 和 Class Pointer,通常占用 128 位。
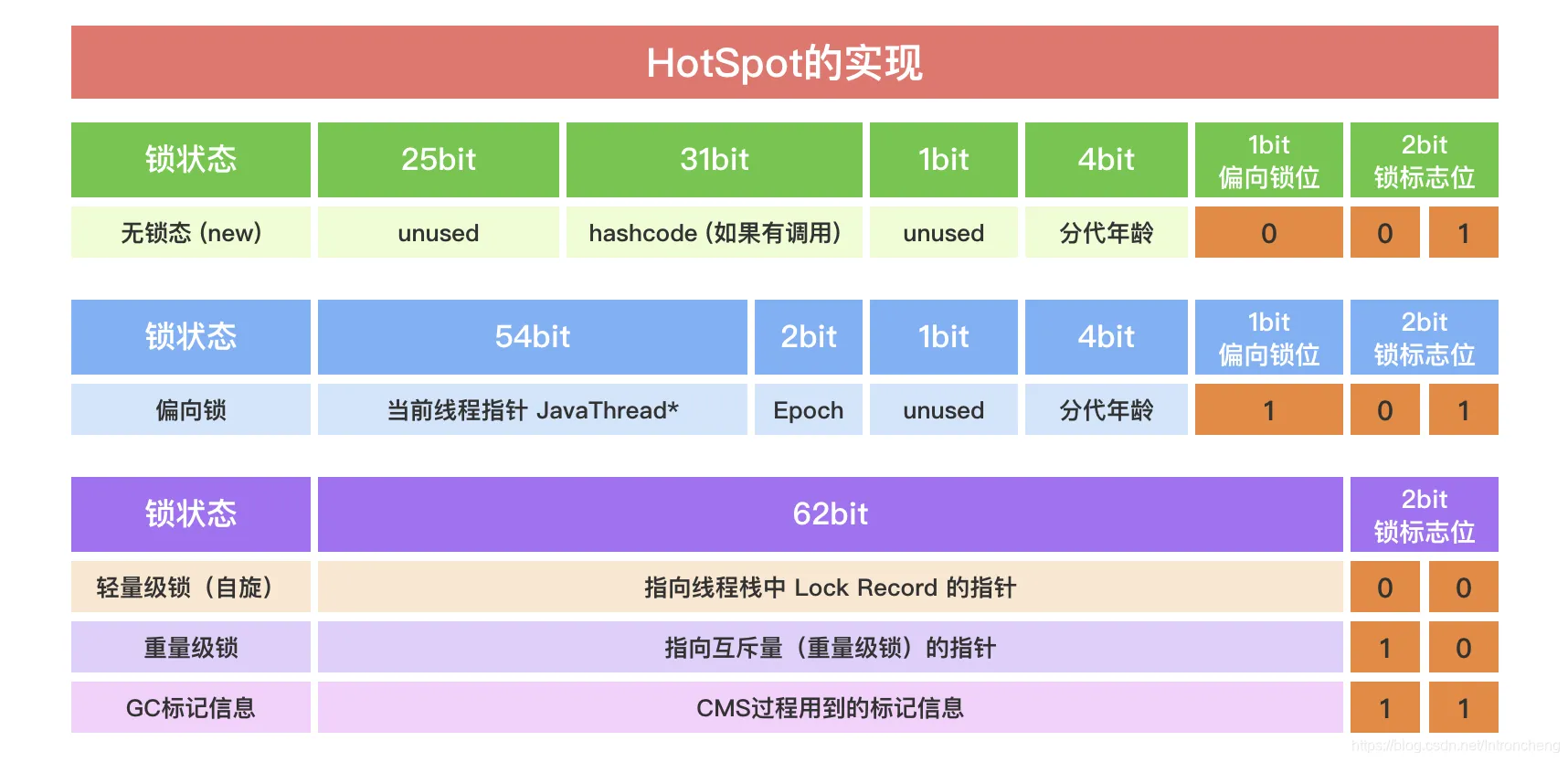
Java 25 通过压缩技术,通过压缩对象头(从 128 位压缩到 64 位),对于大量创建小对象(如 POJO、Integer)的应用,堆内存占用最多可减少 22%,GC 频率降低约 15%,非常适合微服务、云原生容器化部署、高并发对象创建场景。
bash # Java 25 中直接开启(无需实验性参数) -XX:+UseCompactObjectHeaders
语法极简主义:更灵活的构造函数与 Main 方法
灵活的构造函数 (Flexible Constructor)
在 Java 25 之前,super() 或 this() 必须是构造函数的第一条语句,这有时导致验证逻辑无法前置,而 Java 25 解除了这一限制。
java class User extends BaseEntity { private final String email; // Java 25 之前:必须把 super() 放第一行,验证逻辑只能放后面 // Java 25 之后:可以先处理参数,再调用父类构造 User(String email) { // 1. 先对输入进行预处理或验证 if (email == null || !email.contains("@")) { throw new IllegalArgumentException("Invalid email format"); } email = email.strip(); // 标准化输入 // 2. 现在可以放在后面调用 super() 了,逻辑更自然 super(); this.email = email; } }
简化的 Main 方法 (Compact Source)
进一步简化了入门门槛,为了迎合现代脚本语言的习惯,Java 25 允许你像写 Python 一样写 Java 入口,允许使用更简单的 main 方法签名,甚至支持“隐式声明类”,让初学者不用写 public class 就能运行 Java 程序。
java // 不需要写 public class HelloWorld {} // 不需要写 public static void main(String[] args) {} void main() { System.out.println("Hello, Java 25!"); // 直接运行即可,适合写脚本、工具类或教学演示 }
基础类型模式匹配 (Primitive Pattern Matching)
这是模式匹配功能的进一步完善,现在支持直接匹配 int、double 等基本类型,不再需要装箱/拆箱的繁琐操作。
java Object obj = getSomeValue(); // 可能是 Integer, Double 或 String // 传统写法:需要 instanceof Integer,然后强转,再拆箱 // Java 25 写法:直接匹配基本类型 switch (obj) { // 直接匹配 int 类型(自动拆箱) case int i when i > 0 -> System.out.println("正整数: " + i); // 直接匹配 double 类型 case double d -> System.out.println("小数: " + d); // 匹配特定字符串 case String s -> System.out.println("字符串: " + s); default -> System.out.println("其他类型"); }
结构化并发 (Structured Concurrency - 预览/正式)
虽然在之前的版本中有预览,但在 Java 25 中它更加成熟。它将一组并发任务视为一个整体(类似 Go 语言的 Goroutine),简化错误处理和取消操作,避免线程泄漏。
java try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { // 分发两个子任务(例如:查用户、查订单) Future<User> user = scope.fork(() -> fetchUser(userId)); Future<Order> order = scope.fork(() -> fetchOrder(orderId)); // 等待两个任务完成 scope.join(); // 如果任一任务失败,这里会自动抛出异常,且另一个任务会被自动取消 System.out.println("User: " + user.resultNow() + ", Order: " + order.resultNow()); } // 自动关闭,无需手动 shutdown 线程池
总结与建议
JDK 11 作为继 JDK 8 之后的首个长期支持(LTS)版本,是 Java 迈向现代化的转折点,奠定了现代 Java 开发的基础,是摆脱老旧 API 束缚的首选。而 JDK 17 是当前企业级开发的“黄金标准”,它在语法层面带来了革命性的简洁体验。
总体来看 Java 21 是一个 “十年一遇” 的版本,是新时代的并发革命,也是我们新项目的首选。有了 虚拟线程,像写同步代码一样即可实现百万级并发,开发门槛降低,在不同机器上吞吐量提升 10-100 倍;同时又降低了 模式匹配 + Record,可以极简的数据处理,使我们的代码量减少 40%+,Bug 更少;ZGC 新增分代机制,整体上实现了 低延迟 + 高吞吐 + 低 CPU,从而无需在 G1 和 ZGC 之间去做取舍了。
JDK 25 专注于在细节处挖掘性能红利,并为未来的技术挑战做好了准备。
一句话建议:存量项目稳在 17,新项目直接上 21,拥抱虚拟线程,告别线程池焦虑。
本文作者:ZhangHao
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!